Vor kurzem erreichte mich die Email eines Teilnehmers von einem Workshop. In der Email wurde beschrieben, dass eine Abfrage, die in einer Datenbank [A] sehr schnell ausgeführt wird, nach dem Import auf dem gleichen Server als “Data Tier Application” ein sehr viel schlechteres Laufzeitverhalten aufwies, obwohl die neu erstellte Datenbank auf dem gleichen Server mit der gleichen Kompatibilitätseinstellung implementiert wurde.
Inhaltsverzeichnis
Data Tier Application
Eine Data Tier Application (DAC) ist eine logische Datenbankverwaltungsentität, die alle SQL Server-Objekte definiert, die mit einer Benutzerdatenbank verknüpft sind. Eine DAC ist eine in sich geschlossene Einheit der SQL Server-Datenbankbereitstellung, mit der Entwickler und Administratoren SQL Server-Objekte in ein portables Objekt , das sog. „DAC-Paket“, packen können.
BACPAC-Datei
Eine BACPAC-Datei ist eine Windows-Datei mit der Erweiterung „.bacpac“, die das Schema und die Daten einer Datenbank beinhaltet. Der Hauptzweck einer BACPAC-Datei besteht darin, Datenbanken von einem lokalen Server in die Cloud zu migrieren.
DACPAC und BACPAC sind ähnlich, aber sie zielen auf andere Szenarien ab. Ein DACPAC dient zum Erfassen und Bereitstellen von Schemata, einschließlich der Aktualisierung einer vorhandenen Datenbank während eine BACPAC-Datei der Erfassung von Schemas und Daten dient. Dabei werden zwei Hauptoperationen unterstützt.
EXPORT
Der Benutzer kann das Schema und die Daten einer Datenbank in eine BACPAC-Datei exportieren.
IMPORT
Der Benutzer kann das Schema und die Daten in eine neue Datenbank auf dem Hostserver importieren.
Wer mehr über DACPAC und BACPAC erfahren möchte, dem sei der entsprechende Artikel in der SQL Server Dokumentation empfohlen.
Problembeschreibung
Der Kunde exportiert von Server1 eine bestehende Datenbank in eine BACPAC-Datei mit allen Objekten und Daten. Diese BACPAC-Datei wird später in ein Setupprogramm implementiert, um die Anwendung auf den Kundensystemen auszurollen. Nachdem die Datenbank aus der BACPAC-Datei importiert wurde, müssen für die Vervollständigung der Installation diverse Abfragen auf die Datenbank ausgeführt werden. Hierbei kommt es zu erheblichen Verzögerungen bei den Abfragen, die sich auf der Quelldatenbank nicht nachvollziehen lassen.
Demo
Die nachfolgende Demo soll das generelle Problem illustrieren. Dazu wird zunächst eine neue Datenbank erstellt, in der sich lediglich eine Tabelle [dbo].[messages] befindet.
USE demo_db;
GO
-- create the demo table [dbo].[messages]
SELECT * INTO dbo.messages
FROM sys.messages;
GO
-- Create a nonclustered index on [severity]
CREATE NONCLUSTERED INDEX nix_messages_severity
ON dbo.messages (severity);
GO
-- Create a user definied statistics object
CREATE STATISTICS message_id
ON dbo.messages
(
message_id,
language_id
) WITH FULLSCAN;
GO
In der Datenbank existiert – der Übersichtlichkeit wegen – lediglich eine Tabelle mit einem Index (auf dem Attribut [severity]) sowie ein benutzerdefiniertes Statistikobjekt. Anschließend werden drei Abfragen ausgeführt und die Ausführungspläne untersucht.
-- first test query to create an automatic statistics object
SELECT *
FROM dbo.messages
WHERE language_id = 1033
ORDER BY
message_id;
GO
-- second query will use the user defined statistics object
SELECT *
FROM dbo.messages
WHERE message_id = 601
AND language_id = 1033;
GO
-- third query will use the statistics of the index object.
SELECT *
FROM dbo.messages
WHERE severity = 12
ORDER BY
message_id,
language_id;
GO
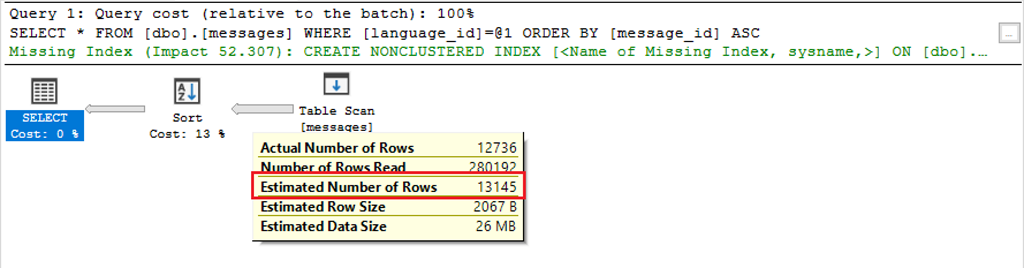
Die erste Abfrage konnte weder einen Index verwenden, noch hatte sie ausreichende Informationen über die zu erwartende Datenmenge. Aus diesem Grund hat Microsoft SQL Server VOR der Ausführung automatisch ein Statistikobjekt erstellt.

Die zweite Abfrage konnte für die Evaluierung der zu erwartenden Datenmenge auf die Benutzerstatistik zugreifen. Es ist hier unerheblich, ob ein SCAN durchgeführt wird.
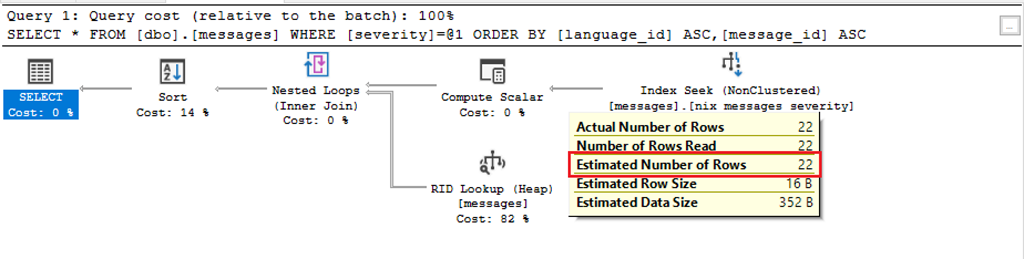
Der Ausführungsplan der dritten Abfrage zeigt, dass Microsoft SQL Server bei der Berechnung von 22 Datensätzen ausgeht, die auch tatsächlich ermittelt werden. Grund für diese exakte Schätzung ist, dass bei der Erstellung eines Index die Statistiken für den Index IMMER mit einem FULLSCAN einhergehen. Da Microsoft SQL Server bei der Erstellung eines Index immer alle Datensätze berücksichtigen muss, wird aus den Daten unmittelbar mit der Erstellung des Index auch das Statistikobjekt erstellt.
Insgesamt sind für die Tabelle [dbo].[messages] nun drei Statistik-Objekte vorhanden.
SELECT * FROM sys.stats WHERE OBJECT_ID = OBJECT_ID(N'dbo.messages', N'U'); GO

XEvent für Protokollierung des Exports
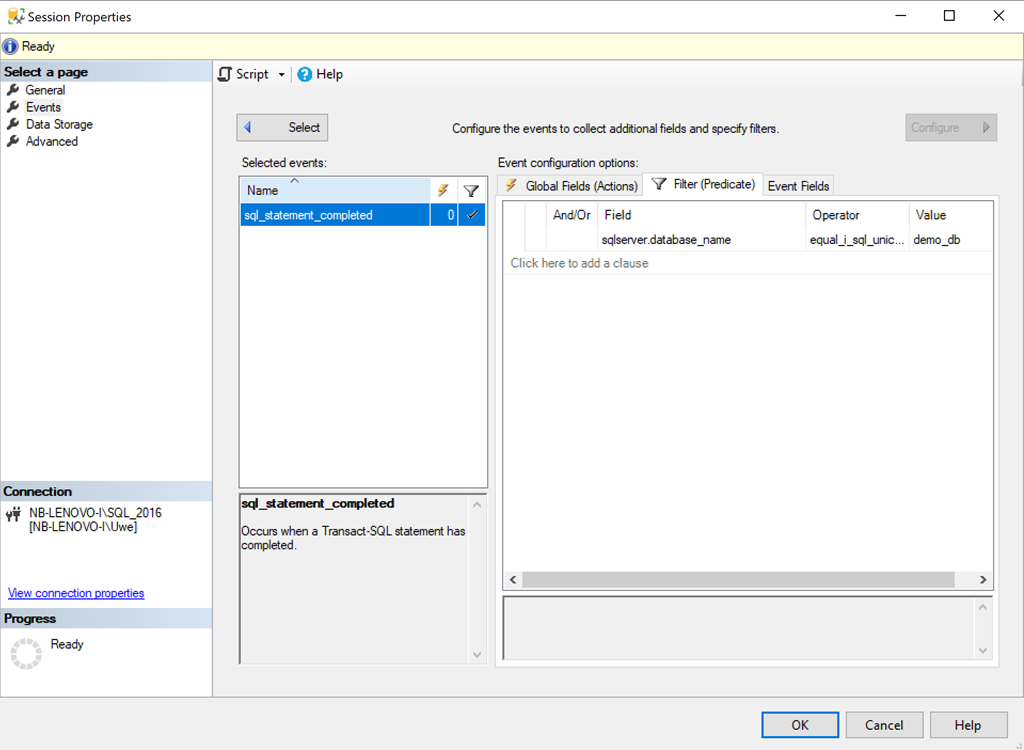
Aus der Datenbank wird im nächsten Schritt eine BACPAC-Datei generiert. Um nachzuvollziehen, was genau bei der Erstellung der Datei in Microsoft SQL Server passiert, protokolliert eine XEvent-Session alle SQL Statements, die während der Erstellung der BACPAC-Datei ausgeführt werden.
IF EXISTS (SELECT * FROM sys.server_event_sessions WHERE name = N'db Database Activity')
DROP EVENT SESSION [db Database Activity] ON SERVER
GO
CREATE EVENT SESSION [db Database Activity]
ON SERVER
ADD EVENT sqlserver.sql_statement_completed
(
WHERE [sqlserver].[equal_i_sql_unicode_string]([sqlserver].[database_name], N'demo_db')
)
WITH
(
MAX_MEMORY = 4096KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 10 SECONDS,
MAX_EVENT_SIZE = 0KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = OFF,
STARTUP_STATE = OFF
)
GO
Export der Datenbank
Um einen Export in eine BACPAC-Datei zu starten, wird mit der rechten Maustaste auf die betroffene Datenbank geklickt. Weiter geht es anschließend mit [Tasks] –> [Export Data-tier Application].


Während des Exports von Schemata und Daten hat die XEvent-Session alle Aktivitäten aufgezeichnet. Neben vielen Vor- und Nachprüfungen und diverserer applikationsbedingter Abfragen ist zu erkennen, dass der Export-Assistent alle Daten aus der Tabelle [dbo].[messages] ausgelesen hat, um sie anschließend in die BACPAC-Datei zu übertragen.
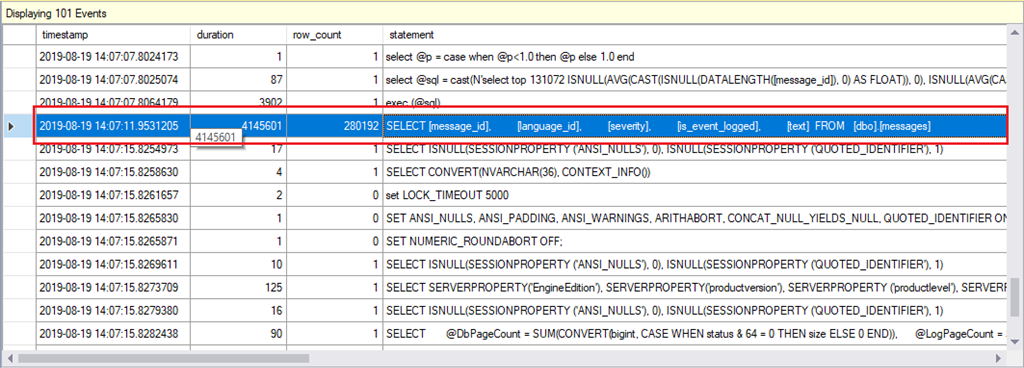
Import der Datenbank
Im nächsten Schritt wird die Datenbank aus der BACPAC-Datei wiederhergestellt. Alle Aktionen werden erneut mit Hilfe des obigen XEvents (neuer Datenbankname!) aufgezeichnet.
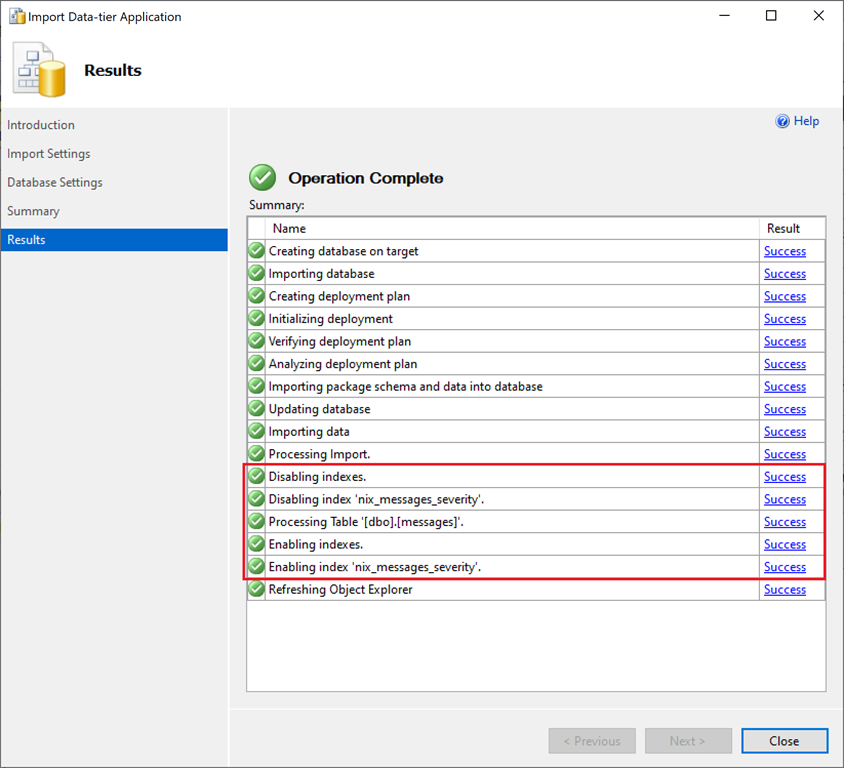
Index(e)
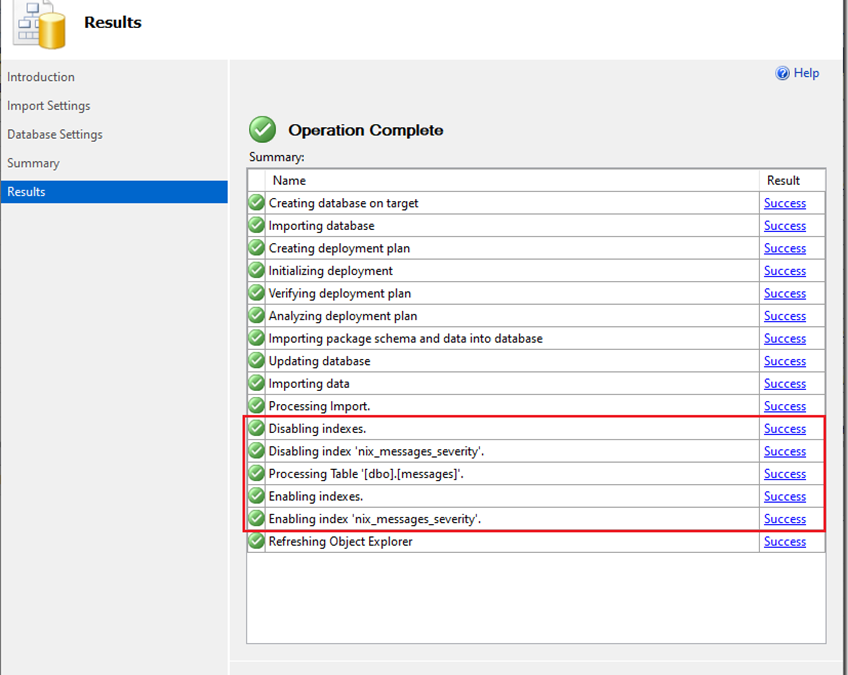
Besonderes Interesse gilt beim Import der Datenbank den rot markierten Auftragsschritten. Nachdem die Datenbank neu angelegt worden ist, werden die Objekte der Datenbank erstellt, bevor die Daten importiert werden können.

Aus den Aufzeichnungen der XEvent-Session geht hervor, dass der Assistent für den Import von Data-Tier-Anwendungen zunächst die Tabelle und anschließend den Index sowie das benutzerdefinierte Statistikobjekt erstellt. Nachdem die Tabelle(n) vollständig angelegt wurden, wird der Index deaktiviert!

Microsoft SQL Server deaktiviert den Index, um die eigentlichen Daten mittels BULK INSERT in die Tabelle einzutragen. Um zu verstehen, warum der Index VOR dem Import der Daten deaktiviert wird, muss man sich mit den Voraussetzungen von “minimal logged” Operationen beschäftigen. BULK INSERT-Operationen sind dann minimal logged, wenn
- die Tabelle keine Indizes besitzt. Dann werden Datenseiten (Tabelle) minimal protokolliert.
- die Tabelle keinen gruppierten Index, aber mindestens einen nicht gruppierten Index aufweist. Dann werden die Datenseiten (Tabelle) minimal protokolliert.
Wie Indexseiten protokolliert werden, hängt jedoch davon ab, ob die Tabelle leer ist
Falls die Tabelle leer ist, werden Indexseiten minimal protokolliert.
- Wenn mit einer leeren Tabelle begonnen wird und die Daten in mehreren Batches importiert werden, werden für den ersten Batch sowohl Index- als auch Datenseiten minimal protokolliert.
- Ab dem zweiten Batch jedoch werden nur Datenseiten minimal protokolliert.
- Falls die Tabelle nicht leer ist, werden Indexseiten vollständig protokolliert.
Ob der Import-Assistent die Daten in mehreren Batches in die Tabelle einträgt, hängt von der Datenmenge ab. Die Beispieltabelle hat ~280.000 Datensätze. Der Import wird vom Assistenten in mehreren Schritten durchgeführt.
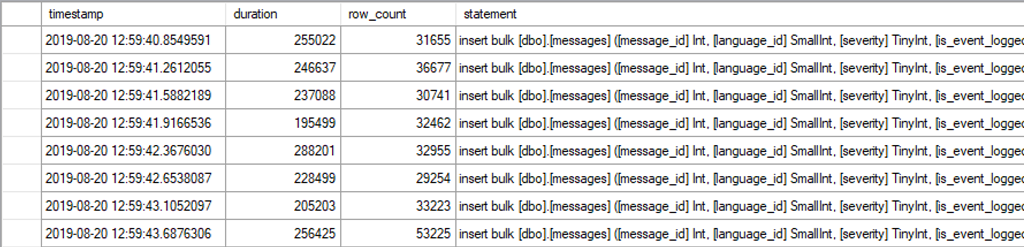
Damit würde der nicht gruppierte Index nur während des ersten Batches minimal logged in die Tabelle geschrieben werden. Jeder weitere Batch würde wieder vollständig protokolliert werden. Die Konsequenz ist ein erhöhtes Transaktionsvolumen und höhere Importdauer auf Grund der Schreibaktivitäten auf der Festplatte.
Nachdem alle Daten in die Tabelle importiert wurden, kann der zuvor deaktivierte Index wieder aktiviert werden.
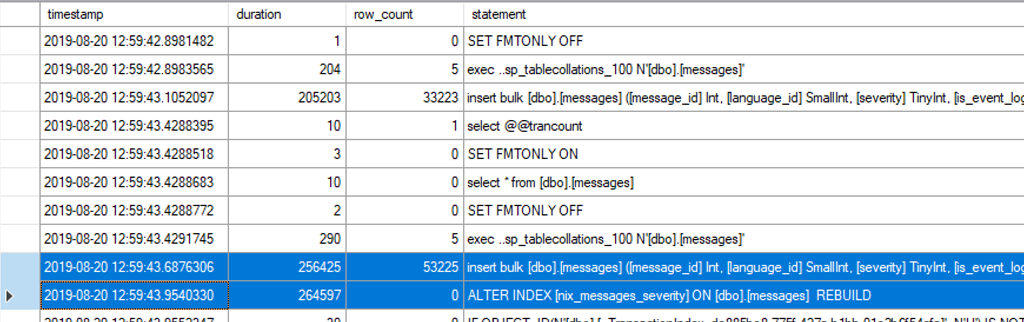
Ein deaktivierte Index kann nicht tatsächlich “aktiviert” werden, sondern muss mit einem REBUILD neu erstellt werden! Siehe dazu auch https://docs.microsoft.com/de-de/sql/relational-databases/indexes/disable-indexes-and-constraints.
Statistiken
Für Statistiken sieht es – LEIDER – nicht immer gut aus.
- Statistiken für Indexe werden mit der Reaktivierung (REBUILD) automatisch neu erstellt. Somit ist – auf Grund der Neuanlage des Index – die Statistik „up to date“
- Benutzerdefinierte Statistiken werden beim Import vom Assistenten neu angelegt. Da benutzerdefinierte Statistiken jedoch VOR dem Datenimport angelegt werden (siehe Abbildung oben), sind die Statistiken LEER und werden bei der ersten Verwendung mit einer “Sample-Rate” aktualisiert.
- Automatisch von Microsoft SQL Server erstellte Statistiken (_WA_Sys_) werden NICHT mit exportiert/importiert!
Der Umstand, dass benutzerdefinierte Statistiken und automatische Statistiken leer oder erst gar nicht erstellt werden, kann zu erheblichen Problemen führen.
Bei der Aktualisierung von Statistiken wird die “Sample Rate” wie folgt berechnet (Quelle: https://blogs.msdn.microsoft.com/srgolla/2012/09/04/sql-server-statistics-explained/)
- Wenn das Datenvolumen der Tabelle <8 MB ist, werden die Statistiken mit einem vollständigen Scan aktualisiert.
- Wenn das Datenvolumen der Tabelle > 8 MB ist, folgt sie folgendem Algorithmus:
- Die “Sample Rate” wird verringert, wenn die Anzahl der Zeilen in der Tabelle erhöht wird, um sicherzustellen, dass nicht zu viele Daten gescannt werden.
- Es ist kein fester Wert, sondern wird vom Optimierer gesteuert.
- Es ist kein linearer Algorithmus.
- Diese “Sample Rate” wird vom Optimierer festgelegt.
Ursache für Einbußen in der Performance von Abfragen
Sicherlich ist schon erkennbar, wo das Problem bei der Verschlechterung der Abfrageperformance liegt. Da sowohl automatische Statistiken als auch Benutzerstatistiken beim Import der Daten nicht aktualisiert werden, verwendet Microsoft SQL Server bei der ersten Abfrage einen “Sample Mode”, der erheblich von den realen Zahlen abweichen kann. Somit kann es dazu kommen, dass Microsoft SQL Server bei der Ausführung von Abfragen nach dem Import mit falschen Schätzungen konfrontiert wird und schlechte Ausführungspläne generiert.
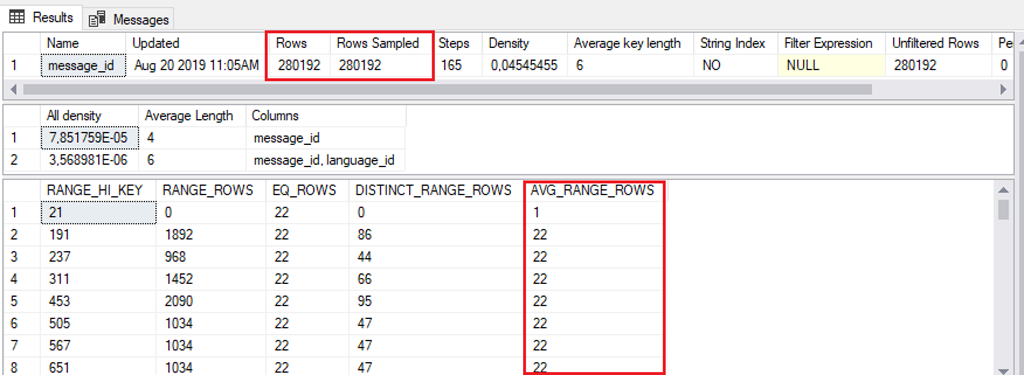
Die obige Abbildung zeigt die benutzerdefinierte Statistik aus der Originaldatenbank. Besondere Beachtung gilt der “Sample Rate”, die bei 100% liegt.
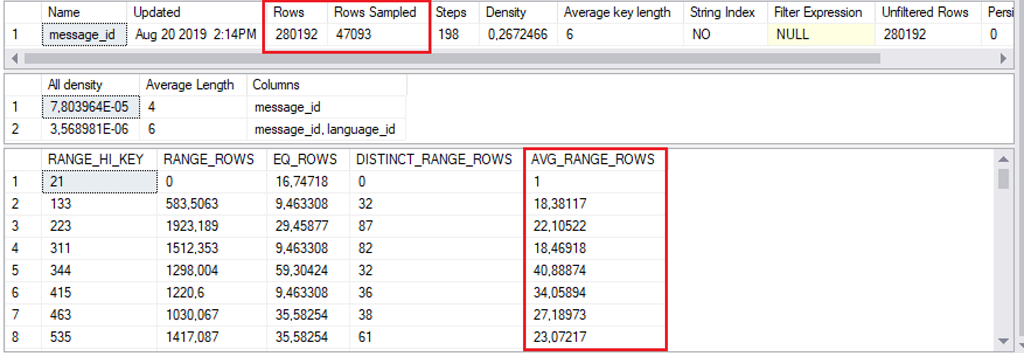
Die zweite Abbildung zeigt exakt die gleiche Statistik, die jedoch beim ersten Ausführen der Abfrage erstellt wurde. Nicht nur die Zahlen selbst machen deutlich, dass hier mit einer “Sample Rate” <> 100% gearbeitet wurde (Nachkommastellen). Auch der Statistic Header lässt erkennen, dass mit deutlich weniger Zeilen die Statistiken neu erstellt wurden. Die Abweichungen in der Demo sind “marginal” – jedoch kann es bei großen Datenmengen zu Verschiebungen kommen, die eine performante Ausführung verhindern.
Lösung des Problems
Damit sichergestellt wird, dass sich Ausführungspläne nach dem Übertragen einer Datenbank mit Hilfe einer bacpac-Datei nicht ändern und gegebenfalls zu Performance-Einbussen führen, sollten nach dem Import der Daten alle Statistiken aktualisiert werden.
DECLARE @stmt NVARCHAR(1024)
DECLARE c CURSOR READ_ONLY FORWARD_ONLY
FOR
SELECT N'UPDATE STATISTICS ' + QUOTENAME(SCHEMA_NAME(T.schema_id)) + N'.' +
QUOTENAME(T.name) + N' ' + QUOTENAME(S.name) + N' WITH FULLSCAN;'
FROM sys.stats AS S
INNER JOIN sys.tables AS T
ON (S.object_id = T.object_id)
WHERE T.is_ms_shipped = 0
AND
(
user_created = 1
OR auto_created = 1
);
OPEN c;
FETCH NEXT FROM c INTO @stmt;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC sp_executesql @stmt;
FETCH NEXT FROM c INTO @stmt;
END
CLOSE c;
DEALLOCATE c;
GO
Vielen Dank fürs Lesen!





