Immer häufiger trifft man auf – vermeintlich – technisch anspruchsvolle Blogeinträge, bei dessen näherer Betrachtung schnell klar wird: Das hat der Autor nicht selbst geschrieben! Das ist ein Artikel aus aus der Feder von ChatGPT und seinen Derivaten. Was geht in den Leuten vor, so einen – teilweise – Mist zu posten, dessen Inhalt scheinbar vom „Autor“ nicht durchdrungen werden kann? AI ist heute in aller Munde – aber die Art und Weise, wie sie für ein paar Minuten Ruhm missbraucht wird, sollte uns alle zum Nachdenken anregen.
Inhaltsverzeichnis
Comparing RIDs and Clustered Index Keys in SQL Server Data Access
So wurde der Blogartikel in einem beruflichen Netzwerk angepriesen. Der Autor erschien schon öfter in meinem Newsfeed. Schon das eine oder andere Mal habe ich gedacht, wie er es schafft, innerhalb von wenigen Stunden gleich 2 – 3 Artikel zu schreiben und zu veröffentlichen.
Hinweis
- Aus Rücksicht auf den/die Autoren eines von mir gefundenen Postings werde ich Textauszüge als Abbildungen zeigen.
- Ich werde nicht auf den Originalpost verlinken!
- Ein tieferes Verständnis für interne Datenstrukturen in Microsoft SQL Server ist von Vorteil
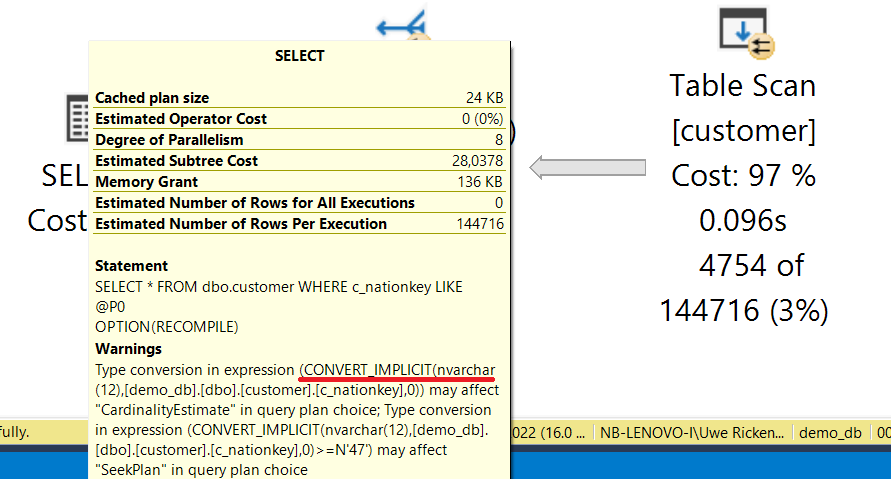
Wie die Überschrift schon vermuten lässt, werden HEAP-Strukturen mit Clustered Index Strukturen verglichen. Während des Lesens sind mir Fehler in der Beschreibung aufgefallen, die – wenn der Autor tatsächlich dieses Wissen hat – bei der Kontrolle hätten auffallen müssen.
HEAPS und RID

Bei diesem Absatz kam das erste Misstrauen auf. Eigentlich sind beide Sätze ein Widerspruch. Zum einen werden RID dazu verwendet, auf Zeilen in einem Non Clustered Index (NCI) zu verweisen. Jedoch gleich darauf wird diese Aussage ad absurdum geführt. NCI speichern IMMER die RID, um so zum Datensatz im Heap zu gelangen und nicht nur, wenn eine Abfrage den NCI verwendet!

Clustered Index und Keys

Der erste Satz ist noch korrekt und danach wird es „schwammig“. Zunächst einmal werden nicht die Datenzeilen der Tabelle in einer B-Tree-Struktur gespeichert sondern das Key-Attribut des geclusterten Index selbst. Diese Struktur führt in den Leaf-Level, der den vollständigen Datensatz bereit hält.
Der letzte Satz mag vielleicht das Richtige meinen ist aber falsch. Auch für einen Index gilt, dass es sich immer um eine LOGISCHE Ordnung handelt! Eine physikalische Ordnung müsste sicherstellen, dass Datensätze auf einer Datenseite verschoben werden. Damit das nicht notwendig ist, gibt es das Slot-Array auf jeder Datenseite, das das Offset des Beginns eines Datensatzes auf der Seite beschreibt.
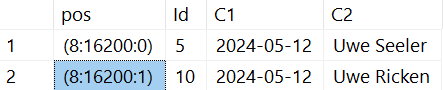
Der Datensatz mit der ID = 5 wird in Slot 0 gespeichert und Datensatz 10 in Slot 1. Das Schlüsselattribut für den Clustered Index ist [Id]. Ein Blick auf das Slot-Array der Datenseite zeigt, dass die Datensätze – physikalisch – genau anders herum gespeichert wurden!

Der Datensatz 0 (Id = 5) wird physikalisch bei Offset 210 gespeichert während Datensatz 1 (Id = 10) am Anfang der Datenseite gespeichert wird.
Fragmentierung in Heaps

Bei dieser Aussage stimmt nur der erste Satz. Datenseiten in einem Heap können nicht fragmentiert sein, da sie keiner logischen Reihenfolge unterliegen. Genau das ist ja das Prinzip eines Heaps! Die Vermutung legt nahe, dass die AI von „FORWARDED RECORDS“ ausgegangen ist. Dabei wird ein Datensatz auf eine neue Datenseite verschoben, wenn er nicht mehr vollständig auf die ursprüngliche Datenseite passt. Dazu wird die neue Position am ursprünglichen Speicherort hinterlegt und SQL Server muss von der ursprünglichen Datenseite zur neuen Position wechseln.
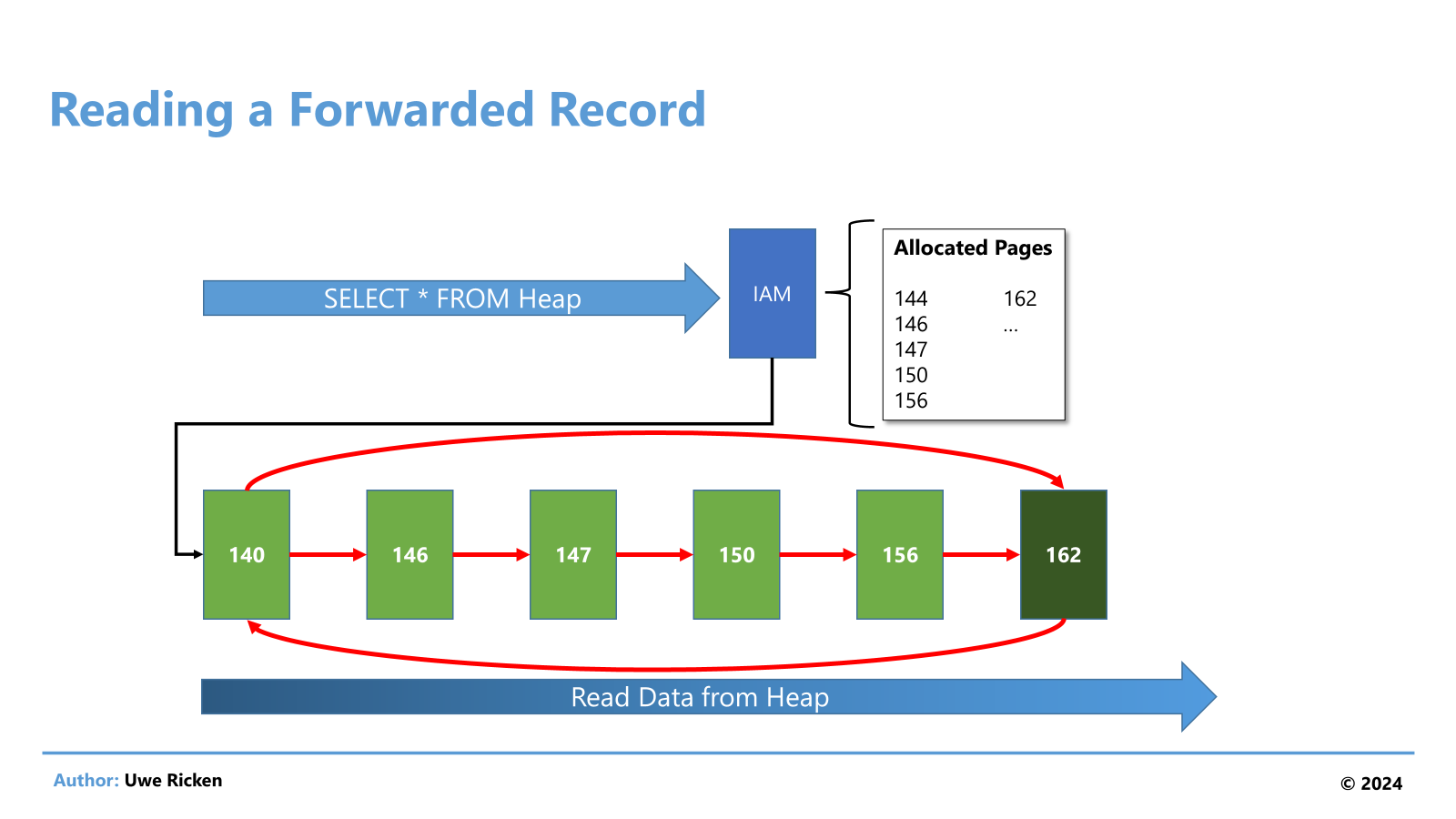
Wenn auf Datenseite 140 ein FORWARD_POINTER auf Seite 162 gespeichert wurde, muss SQL Server beim Lesen der Datenseite für den betroffenen Datensatz auf Datenseite 162 den Datensatz lesen, um anschließend wieder zur Datenseite 140 zurück zu kehren, um den Leseprozess weiter zu führen.
Performance

Fairer Weise muss man sagen, dass die AI sich hier „rettet“, indem sie ein leises „It Depends“ säuselt. Für das Sortieren ist die Aussage nur dann richtig, wenn eine Sortierung auf dem gleichen Attribut erfolgt, wie beim Clustered Index. Wird eine Sortierung auf einem NICHT indexierten Attribut ausgeführt, verhalten sich beide Strukturen gleich. Langsamer beim Scannen der kompletten Tabelle ist nur bedingt richtig (it depends).
Ein Clustered Index muss die B-Tree-Struktur verwalten und beim Scannen der kompletten Tabelle ebenfalls lesen. Wenn man eine reinen IO-Vergleich macht, wird der Heap immer besser abschneiden!
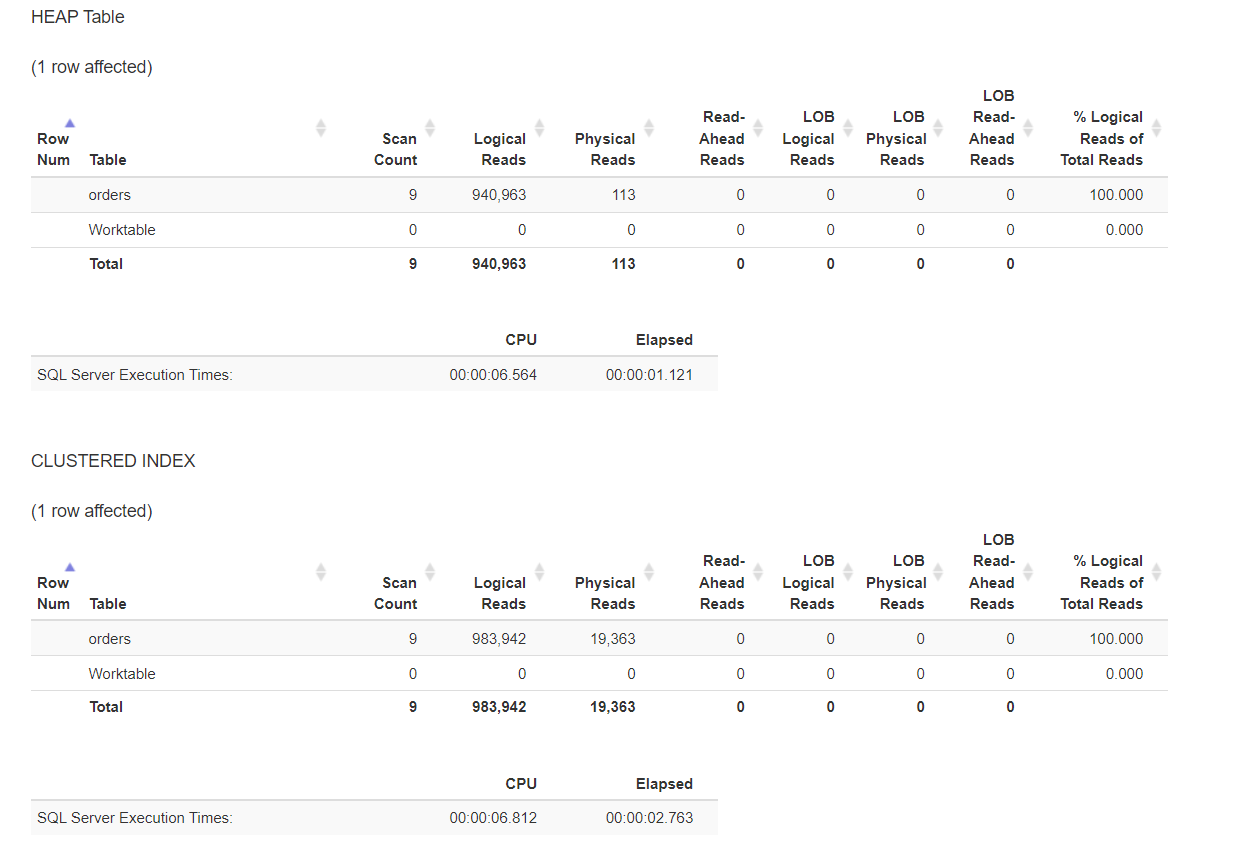
Sowohl in der Kategorie IO als auch in der Kategorie TIME schneidet der Clustered Index schlechter ab. Hier möchte ich aber TIME ausnehmen, da die Tests nicht auf einem isolierten System durchgeführt wurden!
Index Mainteance
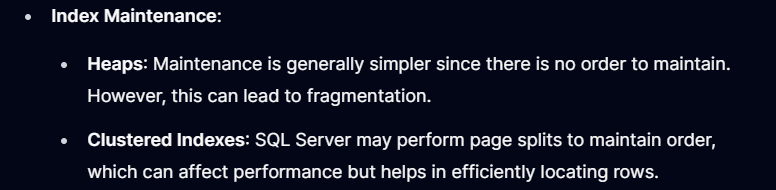
Ein ALTER TABLE … REBUILD (Mainteance) führt also zu Fragmentierungen? Das ist Unsinn, da ein REBUILD dazu führt, dass FORWARDED RECORDS eliminiert werden! Solche Aktionen machen wir aber nur manuell und nicht in regelmäßigen Abständen. Ein REBUILD eines Heaps führt zu einer Veränderung der Position eines Datensatzes. Damit treten wir eine Kettenreaktion los, die dazu führt, dass alle NON CLUSTERED INDEXE aktualisiert werden müssen.
Den zweiten Bulletpunkt muss man sacken lassen. „… page splits … helps in efficently locating rows.“ Index Maintenance bedeutet, die Indexe zu pflegen (REBUILD / REORGANIZE). Wie sollen dabei Page Splits auftreten (o.k. – REBUILD ONLINE) und was haben PAGE SPLIT Operationen mit einer effizienten Ermittlung des Datensatzes zu tun?
Bullshit-Bingo im Finale

Ich überlasse den letzten Absatz der Bewertung durch Dich, geschätzter Leser. Ich weiß nicht, wo genau ich diese Essenz in ihrer Klarheit der Komplexität einordnen soll. Ich denke, es ist … – 42! :)
Vielen Dank fürs Lesen!