
Unit tests/demos in workshops and conference sessions sometimes require a random key value from an existing table. In this article I present a solution that accomplishes this task quickly and in a resource-efficient manner.
Inhaltsverzeichnis
Why an existing – random – key?
The table [dbo].[customers] from the database ERP_Demo contains 1,600,000 rows, which I use for my workshops and regular conference sessions. For a performance test, I need a random customer number [c_custkey] for a process in a stored procedure (e.g. creating an order). However, not just any number can be generated; it must exist in the [dbo].[customers] table!

Problem to find a random key value
A popular trick is to use the function NEWID() to randomly sort a rowset. It is then easy to determine a value using TOP (1).
SELECT TOP (1)
c_custkey
FROM dbo.customers
ORDER BY
NEWID();
Using this method to determine a random key value from small tables is not very complex. However, if – as in this case – it is a table with several million rows, the performance is very poor.
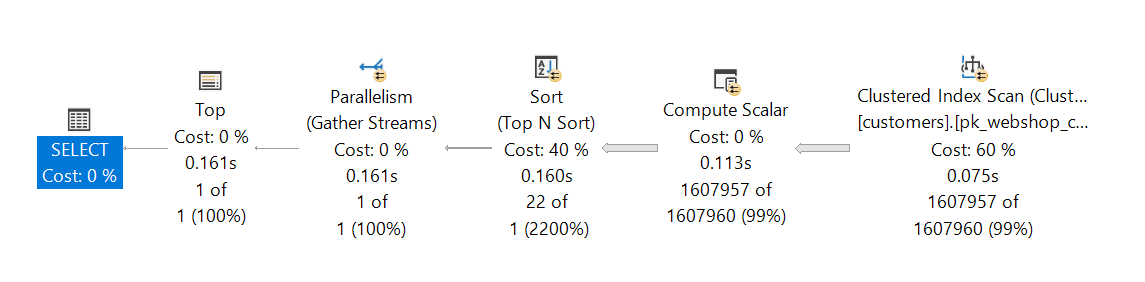
Table 'customers'. Scan count 23, logical reads 28614, ...
SQL Server Execution Times:
CPU time = 1548 ms, elapsed time = 181 ms.The query parallelizes because of the high cost factor, which is caused in particular by the SCAN and SORT operator. The TOP operator comes into play once the 1.6 million rows have been processed. Much too late!
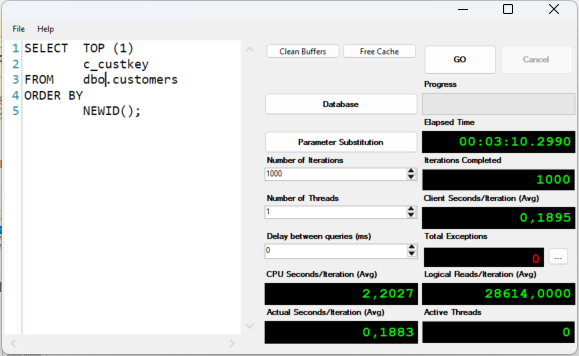
A load test with 1,000 – serialized – runs took more than 3 minutes. These are runtimes we might have been happy with in the days of x86 computers. Nowadays, it has to be faster. The problem with this technique stems from the use of the NEWID() function, which generates an UNIQUEIDENTIFIER for each row and the afterwards – expensive – SORT operation.
SCAN (1.6 Mio) -> NEWID() (1,6 Mio) - SORT (1.6 Mio) -> TOP (1) - OutputAlthough there is an index on the attribute [c_custkey] it won’t help much because all data from the index must be read first before they can be sorted.
Solution to find a random key value efficently
To determine a random value from a table, it is sufficient to take a „random“ row from the table and read the value. The OFFSET clause skips a specified number of rows at the beginning of a result set before presenting the remaining results. It’s often used in conjunction with the ORDER BY clause for paging scenarios in applications.
/* determine a random value between 1 and the number of rows */
DECLARE @row_offset BIGINT = (RAND() * 1607957) + 1;
/* Select the key value from the table */
SELECT c_custkey
FROM dbo.customers
ORDER BY
c_custkey
/* but start at row n and get only 1 row back */
OFFSET @row_offset ROWS FETCH NEXT 1 ROWS ONLY;
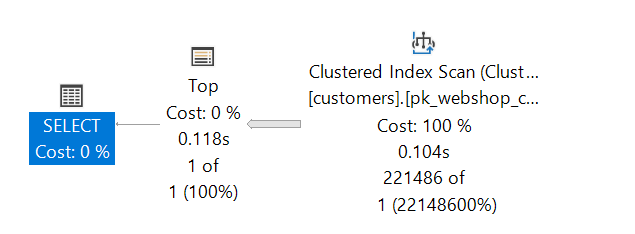
The benefit of this method is that the data no longer needs to be sorted before they are processed by the next operator. It starts outputting the rows from the offset. FETCH NEXT n – clause limits the number of rows to be read.
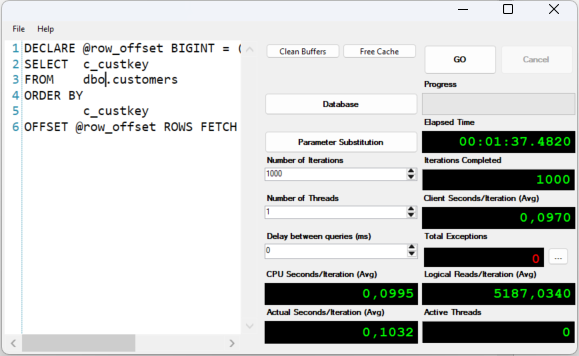
Table 'customers'. Scan count 1, logical reads 3913, ...
SQL Server Execution Times:
CPU time = 78 ms, elapsed time = 119 ms.The performance of the „logical reads“ depend on the offset (that’s the variable) but the costs for the query are so small that SQL Server will not parallelize the query anymore. The data stream (SCAN) is straight forward and follows the index – no need for distribution of work over multiple cores.
Thank you for reading!





