
In the realm of data management, maintaining optimal query performance is paramount. Microsoft SQL Server provides a powerful feature—automatically generated statistics objects—that plays a crucial role in this endeavor. These statistics objects are vital for the Query Optimizer to make decisions about the most efficient execution plans, resulting in faster query performance and reduced resource consumption.
Inhaltsverzeichnis
What are automatically created statistics?
Automatically generated statistics objects are created by SQL Server to gather metadata about the distribution of data within columns of tables. This metadata helps the query optimizer estimate the number of rows that will be returned by a query, leading to more accurate and efficient execution plans.
Automatically generated statistics differ from statistics generated manually or when creating indexes. You can usually identify them by the fact that they start with the prefix „_WA_sys„.
Benefits
- Reduced manual effort because statistics don’t need to be created by the developers/database administrators
- The Query Optimizer can choose the most efficient execution plan
When they are created
- When a query is executed the first time and the Query Optimizer determines that statistics are needed for a column.

Auto created statistics in large tables
Statistics in Microsoft SQL Server are automatically created under the following conditions:
- When a query references a column without existing statistics, SQL Server may automatically create statistics to help the query optimizer make better decisions.
- If a query involves joins, filters, groupings, or other constructs that require data distribution information, and statistics are not available, SQL Server will create them.
These automatically generated statistics help ensure that the query optimizer has accurate and current information to produce efficient execution plans, leading to better query performance and resource utilization. That sounds cool. But it has a significant disadvantage when accessing a table object with a very large amount of data for the first time: first the statistics are created and then the query can be executed. And that can take some time. I use my demo database, which I use for my workshops and my conference sessions, as an example.
USE ERP_Demo;
GO
/* Schema in ERP_Demo for the blog post about auto created statistics */
CREATE SCHEMA [demo] AUTHORIZATION dbo;
GO
DROP TABLE IF EXISTS demo.lineitems;
GO
/* Create a demo table with 82.831.637 rows. */
SELECT *
INTO demo.lineitems
FROM dbo.lineitems WITH (READPAST);
GO
/*
Start the DISTINCT query to create a statistics object for every column
Note: The DISTINCT forces SQL Server to create a stats object for every
output column!
*/
SELECT DISTINCT
*
FROM demo.lineitems
GO

I have shortened the output of the extended event for better readability. However, the figure shows two things very clearly:
- Creating the statistics took about 10 seconds.
- After the statistics were created, the query was started
/* Get a list of all stats objects for the demo table */
SELECT object_id,
stats_id,
stats_name,
auto_created,
stat_columns
/*
The function is part of the framework of the demo database!
GIST: https://gist.github.com/uricken1964/b3b31b33dadcbc3252ba2488d3c6961c
*/
FROM dbo.get_statistics_columns_info(N'demo.lineitems', N'U');
GO
To list the statistics objects, use a function I wrote that is available in the framework of my demo database or can be loaded from my GIST repositories.
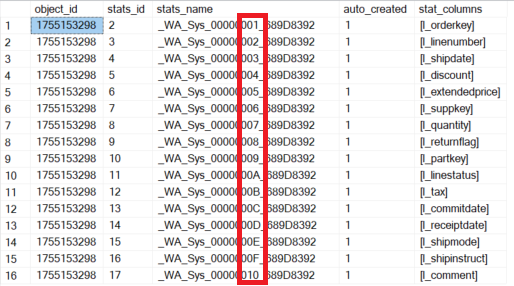
The red block represents the ordinal value of the attribute in the table as a hexadecimal value. Even if the example looks a bit „contrived“, it is clear that creating statistics takes time. The time will increase as there are more rows and columns in the table.
Note: „There is no lunch for free!“
The creation of automatic statistics can be avoided in DISTINCT queries by giving the table a unique key before the execution of the query. The Key Attribute must be included in the SELECT statement.
DROP TABLE IF EXISTS demo.lineitems;
GO
/* Create a demo table with 82.831.637 rows. */
SELECT *
INTO demo.lineitems
FROM dbo.lineitems WITH (READPAST)
WHERE 1 = 0;
GO
ALTER TABLE demo.lineitems ADD CONSTRAINT pk_demo_lineitems PRIMARY KEY NONCLUSTERED
(
l_orderkey,
l_linenumber
);
INSERT INTO demo.lineitems WITH (TABLOCK)
SELECT * FROM dbo.lineitems WITH (READPAST);
GO
SELECT DISTINCT
*
FROM demo.lineitems
GO
/* Get a list of all stats objects for the demo table */
SELECT object_id,
stats_id,
stats_name,
auto_created,
stat_columns
FROM dbo.get_statistics_columns_info(N'demo.lineitems', N'U');
GO
The presence of a unique key is sufficient for Microsoft SQL Server to determine that the index/constraint ensures that each row is unique.
This works for the following implementations:
- PRIMARY KEY Constraint
- UNIQUE Constraint
- UNIQUE CLUSTERED INDEX
- UNIQUE NONCLUSTERED INDEX
Redundant Statistics
Another unpleasant feature of automatic statistics is the possible redundancy of statistics objects when – for example – indexes or manual statistics objects are created. Microsoft SQL Server does not check whether a statistics object with the same definition already exists.
DROP TABLE IF EXISTS demo.customers;
GO
/* Insert 1.600.000 rows into the table */
SELECT *
INTO demo.customers
FROM dbo.customers WITH (READPAST)
GO
/* Execute the query to create the automatic statistics */
SELECT DISTINCT
*
FROM demo.customers
GO
ALTER TABLE demo.customers ADD CONSTRAINT pk_demo_customers PRIMARY KEY CLUSTERED
(c_custkey);
/*
Get a list of all stats objects for the demo table
Note: Statistics 1 and 2 are identically!
*/
SELECT object_id,
stats_id,
stats_name,
auto_created,
stat_columns
FROM dbo.get_statistics_columns_info(N'demo.customers', N'U');
GO
The above example creates the table [dbo].[customers] and immediately performs a SELECT. This creates the automatic statistics. Only then is a primary key created.
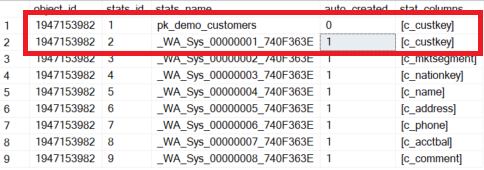
Pay attention to the two statistics objects that reference the attribute [c_custkey]! Identical statistics have no direct impact on the performance of a query, as the query optimizer recognizes the redundancy and always chooses the index statistics. However, two points should not be overlooked:
- Maintenance tasks require more time to update all statistics!
- Both statistics objects must be updated
/* Show the execution time for the update of statistics */
DBCC TRACEON (3604, 8721);
GO
/* Úpdate all statistics objects with FULLSCAN */
UPDATE STATISTICS demo.customers WITH FULLSCAN;
GO
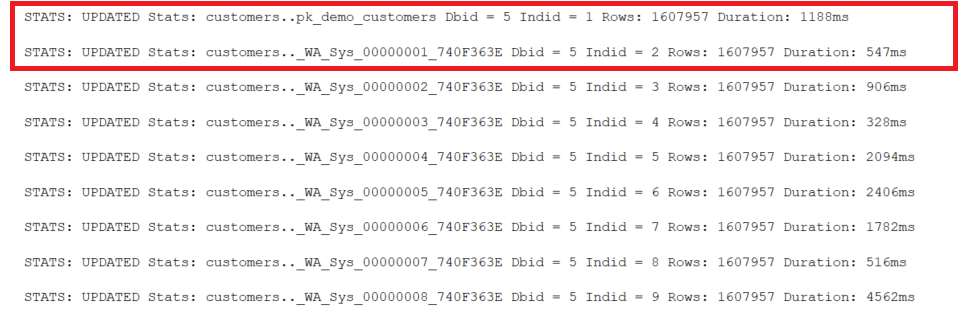
The update of all statistics objects took app. 14 seconds and this table has only 1.6 Mio rows. Think big! What happens with your maintenance in a multi-billion table when the maintenance will update all modified statistics with a full scan?
Thank you very much for reading!



